About The Projects
The record does not lie. It accumulates. What governments release, we release — all of it, without exception. We follow power through public files: financial networks, government contracts, intelligence operations. We do not speculate. We do not editorialize. We connect dots and publish the roadmaps. Everything we publish carries the documents it came from. The files speak plainly. We make certain they are heard.
Each investigation The Projects undertakes builds its own dedicated database — purpose-built for that corpus, that set of questions, that body of public record. The databases are not public search engines. They are forensic tools, access-controlled, with every result tied to a citable primary source document.
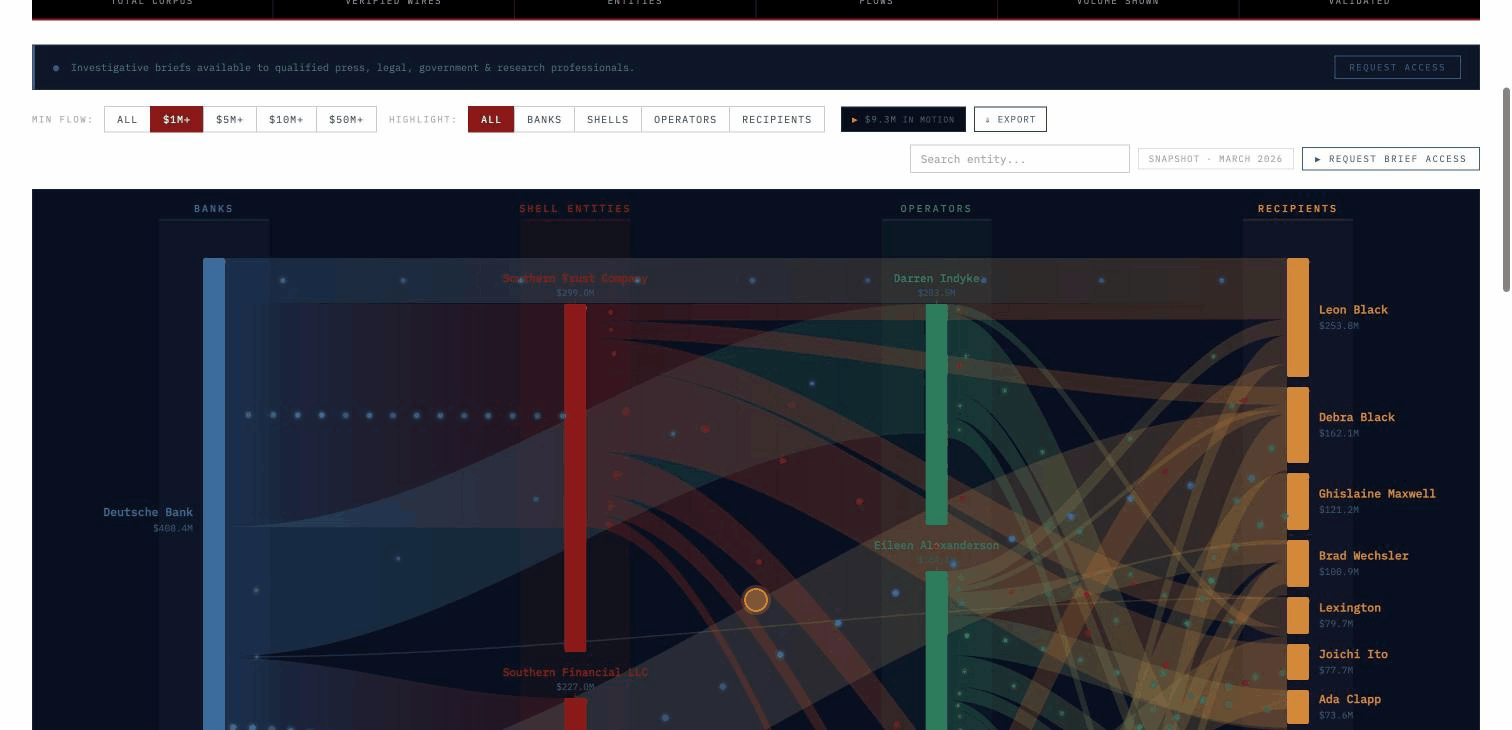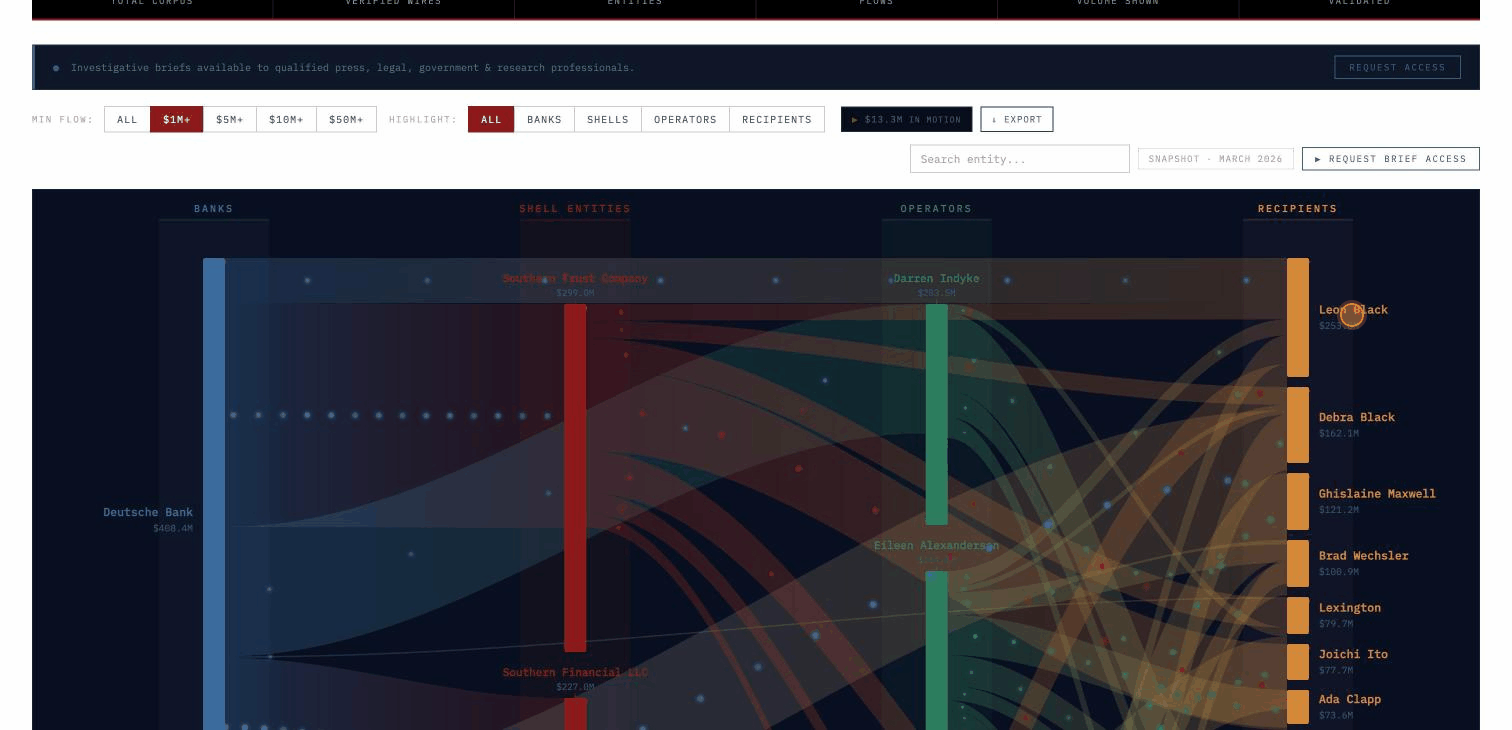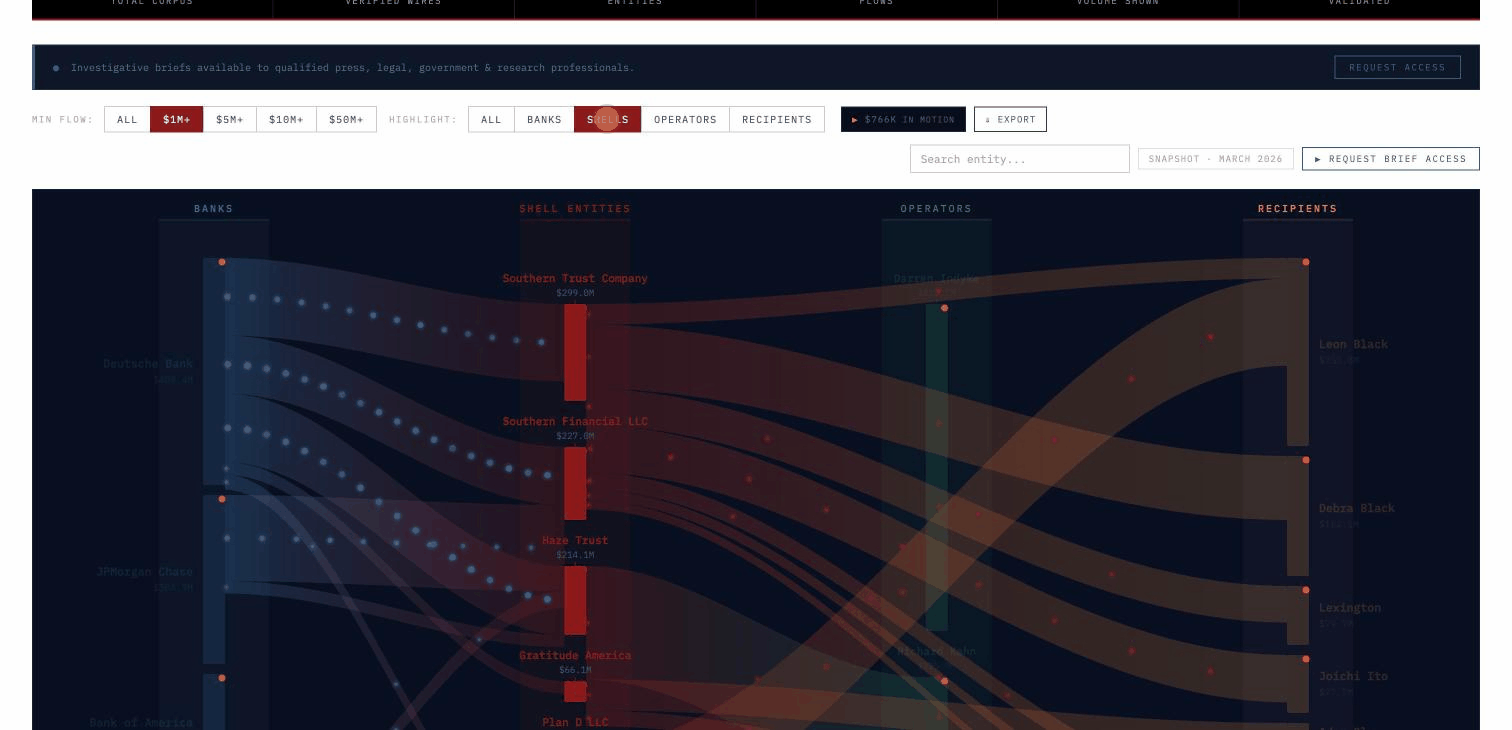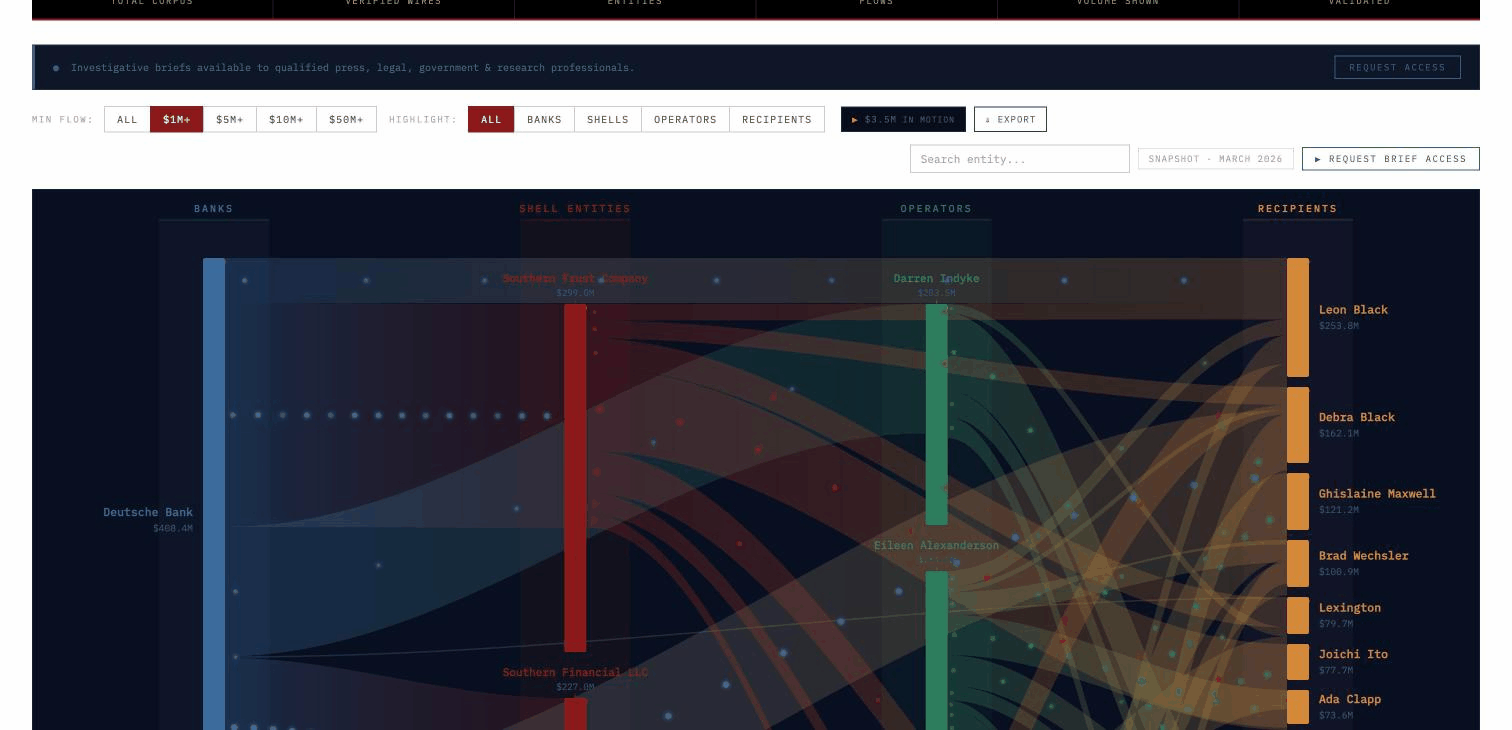
The current active database covers the complete DOJ-released Epstein document corpus — 1,476,437 files (2.87 million pages) across all production sets — 1.124 million emails, 204,000 general documents, 42,000 financial records, 23,000 court filings, and 245,384 native media files with full text extracted and cross-referenced. The financial layer covers $2.146 billion in verified transactions linked directly to source documents. Audio transcripts from grand jury depositions, SDNY tip voicemails, and prison calls are indexed and searchable. A forthcoming database will cover the full federal procurement record — over $6 trillion in contract awards across every agency and administration.
Every result ties to citable DOJ source documents with a live link, so anything surfaced is immediately usable for oversight — briefings, hearings, referrals. Nothing leaves the system unless a user deliberately exports it.